Lab 3.3 Scenario 3: Evaluate your models using Prompt Flow to keep optimizing
概要
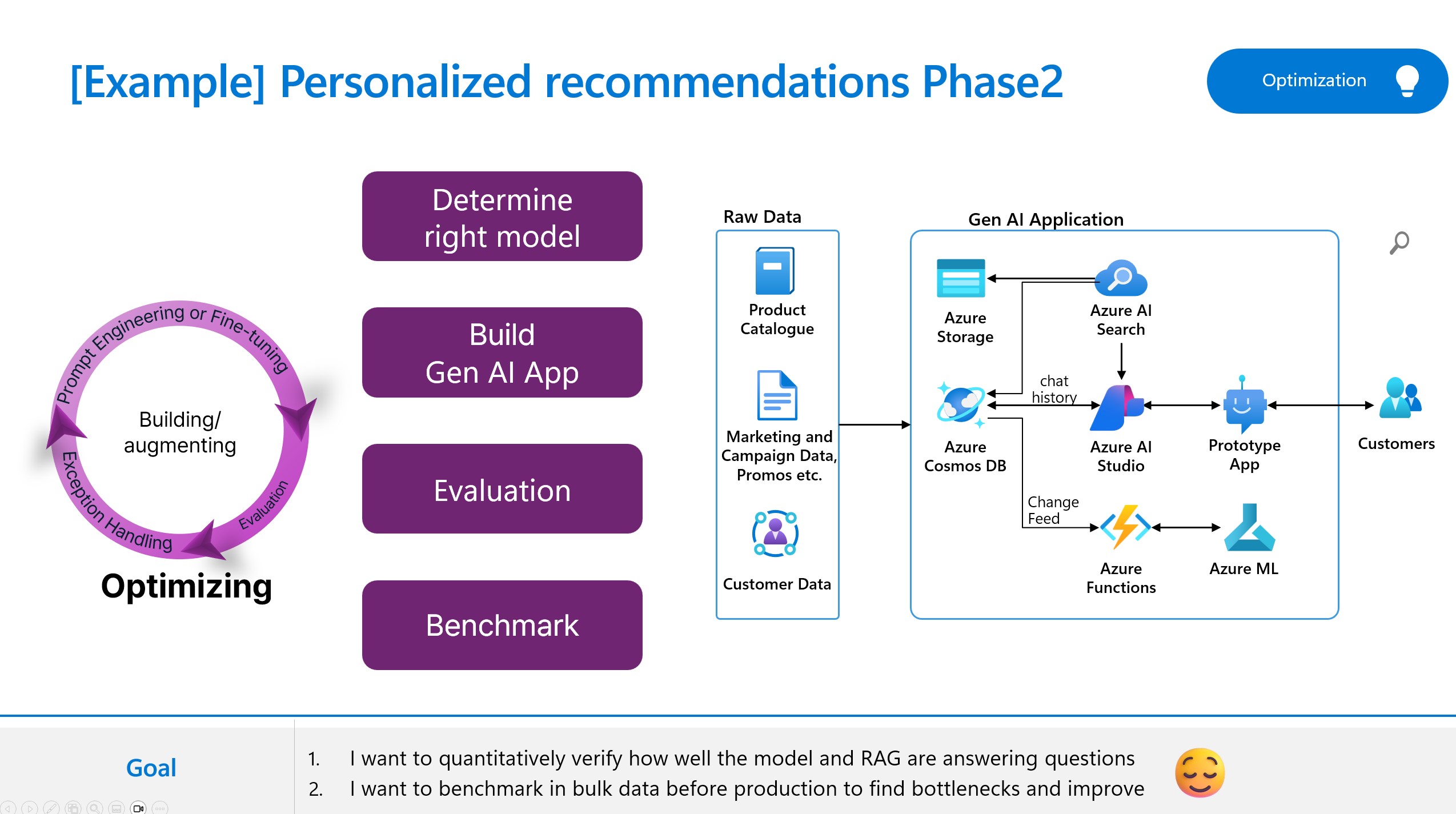
このラボでは、Azure AI Foundry の AI を活用した評価機能を探索し、LLM ノードで A/B テストを実行して、プロンプトと LLM のパフォーマンスを評価します。さまざまな表現、書式設定、コンテキスト、温度、top-kなど、さまざまな条件下でモデルの動作をテストし、モデルの精度、多様性、または一貫性を最大化する最適なプロンプトと構成を比較し、見つけるのに役立つバリアントの作成方法を学びます。
その他のリソース
ここでは、このトピックに関するリファレンスアーキテクチャ、ベストプラクティス、およびガイダンスを示します。以下のリソースを参照してください。
- https://learn.microsoft.com/en-us/azure/ai-studio/concepts/evaluation-approach-gen-ai
- https://github.com/Azure-Samples/llm-evaluation